录音转文字软件 高效办公与计算机软件开发设计的新利器
在当今信息时代,高效处理音频信息的需求日益增长,录音转文字电脑软件应运而生,成为众多行业提升工作效率的得力工具。这类软件主要利用语音识别技术,将音频文件中的语音内容自动转换为可编辑的文本。它究竟怎么样?能否快速完成转换?其背后又与计算机软件开发设计有着怎样的紧密联系呢?
从用户体验来看,现代主流的录音转文字软件已经相当成熟。其核心优势在于“快速”和“便捷”。对于清晰的录音文件,软件通常能在几分钟甚至更短时间内,完成长达一小时的音频转换,速度远超传统的人工听写。这极大地解放了人力,尤其适用于会议记录、访谈整理、课堂笔记、媒体内容生产等场景。用户只需将音频文件(如MP3、WAV等格式)导入软件,选择相应的语言和识别模型,即可启动转换过程。许多软件还支持实时录音转写,即在说话的文字便同步生成在屏幕上。
转换的“快速”与“准确”往往是一对需要平衡的矛盾。转换速度受多种因素影响:一是计算机的硬件性能,特别是CPU和内存;二是音频文件的质量,清晰、无过多背景噪音的录音识别率更高、速度更快;三是软件所采用的算法模型。目前,基于深度学习的端到端模型大大提升了识别效率和准确率。但面对专业术语、浓厚口音或多人嘈杂对话的场景,识别准确率可能会下降,通常需要后期人工校对进行修正。因此,“快速”是相对的,高质量的输入和合理的预期是获得满意结果的关键。
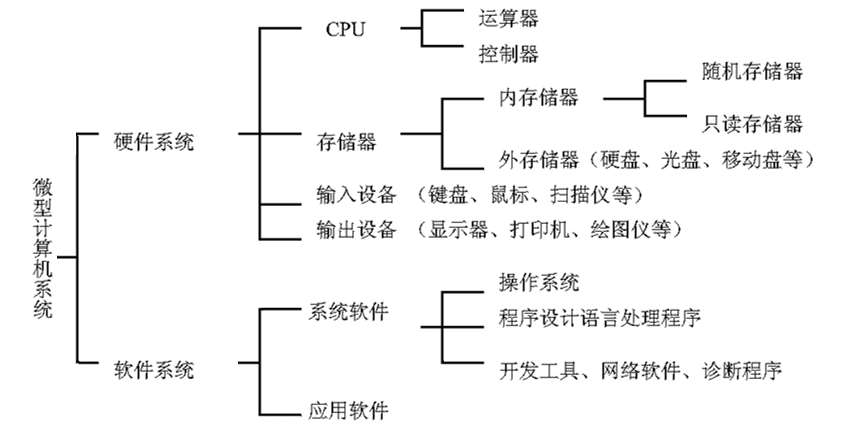
从技术层面深入,录音转文字软件的蓬勃发展,正是计算机软件开发与设计领域进步的缩影。其开发过程涵盖了多个关键技术环节:
- 信号处理与前端处理:软件开发首先需设计音频预处理模块,负责降噪、回声消除、语音端点检测(判断哪里是说话的开始与结束)等,为后续识别提供干净的语音信号。
- 核心算法模型(语音识别引擎):这是软件的核心。早期多采用隐马尔可夫模型(HMM)与高斯混合模型(GMM)的结合。如今,主流方案是基于深度神经网络(DNN),尤其是循环神经网络(RNN)、长短时记忆网络(LSTM)以及当前最先进的Transformer架构(如Conformer模型)。这些模型通过海量的语音-文本配对数据进行训练,学习从声音特征到文字单元的复杂映射。软件设计需要高效集成这些模型,并可能针对特定领域(如医疗、法律)进行优化训练。
- 语言模型与后处理:识别出的原始文本序列需要通过语言模型(通常也是大型神经网络,如N-gram或神经网络语言模型)进行纠错和顺滑,使其更符合语法和上下文逻辑。后处理还包括标点符号预测、数字格式规范化等。
- 软件工程与系统设计:要将算法转化为用户可用的产品,需要精湛的软件工程设计。这包括:
- 架构设计:考虑是采用本地客户端处理(对算力要求高,但隐私性好)还是云端服务(便于更新模型、利用强大算力,但依赖网络)。
- 用户界面(UI)与用户体验(UX)设计:设计直观易用的操作界面,实现文件拖拽、进度显示、文本编辑、导出多种格式等功能。
- 性能优化:确保软件运行流畅,内存占用合理,转换过程稳定高效。
- 兼容性与集成:确保软件能在不同操作系统(Windows、macOS、Linux)上运行,并能与其他办公软件(如Word、Excel)顺畅集成。
软件开发中还涉及大数据处理(用于训练)、云计算平台的使用(部署服务)、以及可能的移动端适配(与手机App同步)等广泛知识。
一款优秀的录音转文字软件,已经能够相当快速地将常规录音转换为文字,成为提升生产力的实用工具。而其从构想变为现实的过程,则深度融合了人工智能、数字信号处理、软件工程、用户体验设计等计算机科学与技术的多个分支。它的不断进化,持续推动着语音识别领域算法模型的创新,也对软件开发者在系统架构、性能调优和产品化能力方面提出了更高要求。随着多模态识别(结合语音、语义、上下文)和个性化自适应模型的进一步发展,录音转文字软件必将变得更加智能、精准和人性化。
如若转载,请注明出处:http://www.lingyunshangcheng.com/product/18.html
更新时间:2026-06-19 20:19:13